背景
在了解了单机单卡的模型加载过程后,我们看看单机多卡的场景。单机单卡流程简单,但是在实际场景中要想运行真正的大模型需要的显卡数量肯定不可能是1张,这里我们再看看单机多卡的情况下的整体流程
整体流程
借用猿姐的神图
整体架构:
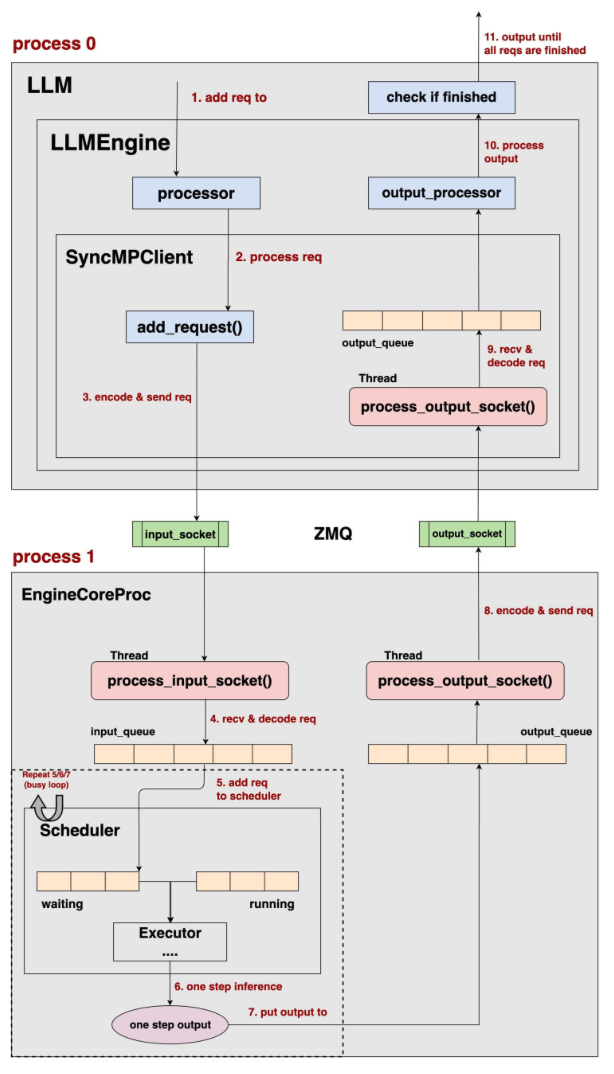
分为三大块:
- process0:AsyncLLM
- process1: Executor+scheduler
- process2: Worker
其中executor->worker架构:
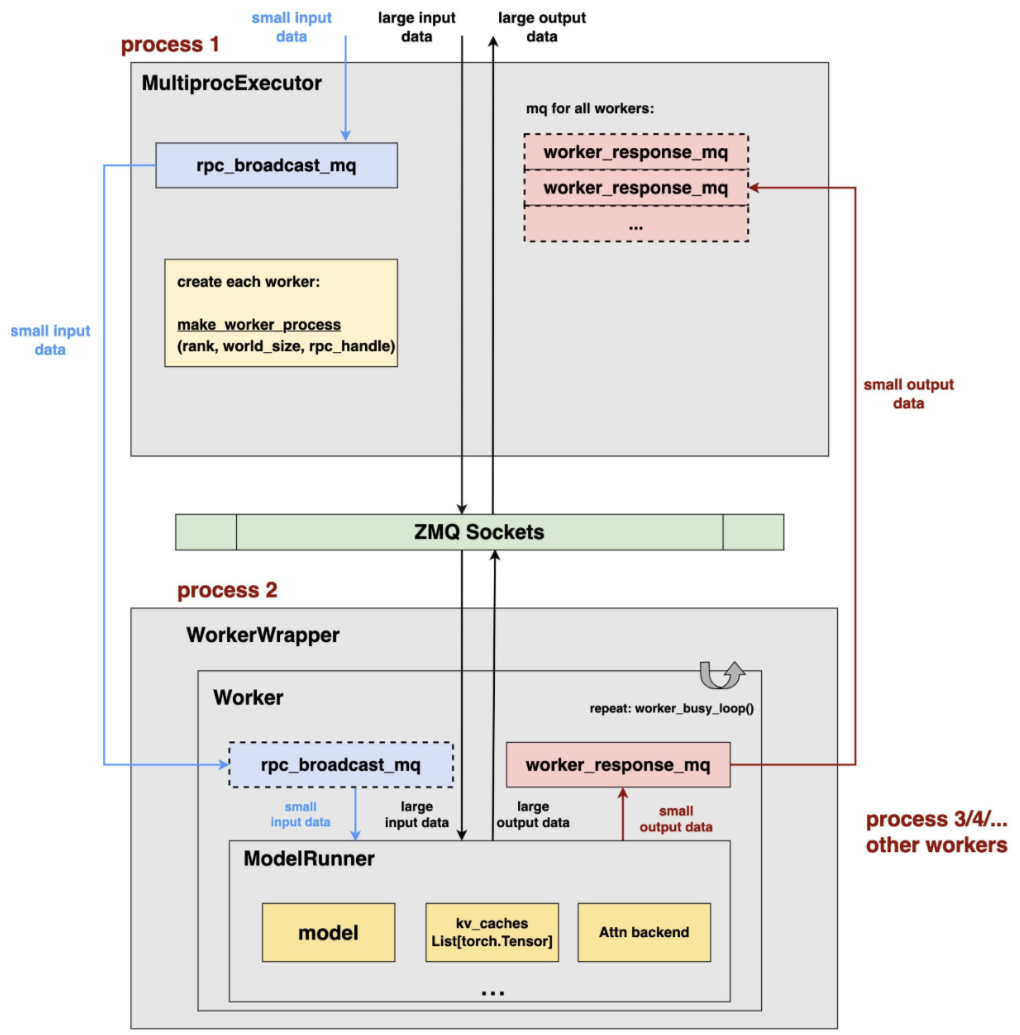
executor->worker的流程中,executor是一个独立的进程,每个worker是一个独立的进程,图中为了方便只画了一个worker来说明
process0:AsyncLLM
主要工作:
- 生成vllm配置
- 加载分词器
- 创建input_process:preprocess input request,通过engine_core的input_socket发送
- 创建output_process:获取engine_core output_socket返回的结果,进行处理后放入outputs_queue
- 创建engine_core: 创建一个调用engine的client,上面的input_socket和output_socket都是在这里创建的
- 创建dp_size对应数量的core_engine进程并启动
AsyncLLM初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
class AsyncLLM(EngineClient):
def __init__(
...
) -> None:
...
# 加载分词器
if self.model_config.skip_tokenizer_init:
tokenizer = None
else:
tokenizer = init_tokenizer_from_configs(self.model_config)
# input_process,用来预处理request并通过input_socket发送到enginecore_proc
self.processor = Processor(self.vllm_config, tokenizer)
self.io_processor = get_io_processor(
self.vllm_config,
self.model_config.io_processor_plugin,
)
# 在初始化的最后用output_process循环处理output_socket收到的数据
self.output_processor = OutputProcessor(
self.tokenizer, log_stats=self.log_stats
)
...
# EngineCore (starts the engine in background process).
self.engine_core = EngineCoreClient.make_async_mp_client(
vllm_config=vllm_config,
executor_class=executor_class,
log_stats=self.log_stats,
client_addresses=client_addresses,
client_count=client_count,
client_index=client_index,
)
...
# 一直在循环处理从output_socket中获取的数据
self.output_handler: asyncio.Task | None = None
try:
# Start output handler eagerly if we are in the asyncio eventloop.
asyncio.get_running_loop()
self._run_output_handler()
except RuntimeError:
pass
...
创建socket
这里在AsyncLLM初始化engine_core_manager对象时,会创建两个zmq socket,分别是input_socket和output_socket。 这里的两个socket会在input_process和output_process中被使用 同时AsyncMPClient中还会创建output_queue,output_process将output_socket收到的数据处理好后会放入output_queue中 到这里可以看到input_socket和output_socket都是ZMQ 连接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
class MPClient(EngineCoreClient):
def __init__(
self,
asyncio_mode: bool,
vllm_config: VllmConfig,
executor_class: type[Executor],
log_stats: bool,
client_addresses: dict[str, str] | None = None,
):
self.vllm_config = vllm_config
# Serialization setup.
self.encoder = MsgpackEncoder()
self.decoder = MsgpackDecoder(EngineCoreOutputs)
# ZMQ setup.
sync_ctx = zmq.Context(io_threads=2)
self.ctx = zmq.asyncio.Context(sync_ctx) if asyncio_mode else sync_ctx
...
self.resources = BackgroundResources(ctx=sync_ctx)
self._finalizer = weakref.finalize(self, self.resources)
success = False
try:
# State used for data parallel.
self.engines_running = False
self.stats_update_address: str | None = None
if client_addresses:
# Engines are managed externally to this client.
input_address = client_addresses["input_address"]
output_address = client_addresses["output_address"]
self.stats_update_address = client_addresses.get("stats_update_address")
else:
# 加载模型库和权重文件,内部还有rpc的建立,我们后面详细看
with launch_core_engines(vllm_config, executor_class, log_stats) as (
engine_manager,
coordinator,
addresses,
):
self.resources.coordinator = coordinator
self.resources.engine_manager = engine_manager
(input_address,) = addresses.inputs
(output_address,) = addresses.outputs
self.stats_update_address = addresses.frontend_stats_publish_address
if coordinator is not None:
assert self.stats_update_address == (
coordinator.get_stats_publish_address()
)
# 创建 input 和 output sockets.
# input_socket是发送端,支持多个core_engine来连接
self.input_socket = self.resources.input_socket = make_zmq_socket(
self.ctx, input_address, zmq.ROUTER, bind=True
)
# 对于output_socket,这里的socket type是PULL,表示是接收端,和图中箭头一致
self.resources.output_socket = make_zmq_socket(
self.ctx, output_address, zmq.PULL
)
...
创建engine_core_manger
根据dp_size来创建对应数量的engine_core进程并启动 这里的target_fn参数是EngineCoreProc.run_engine_core函数 handshake_address参数是ZMQ input和output地址,且在前面已经创建连接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
class CoreEngineProcManager:
def __init__(
...
):
...
self.processes: list[BaseProcess] = []
local_dp_ranks = []
# 这里根据dp_size来创建对应数量的engine_core进程
for index in range(local_engine_count):
local_index = local_start_index + index
global_index = start_index + index
# Start EngineCore in background process.
local_dp_ranks.append(local_index)
self.processes.append(
context.Process(
target=target_fn,
name=f"EngineCore_DP{global_index}",
kwargs=common_kwargs
| {
"dp_rank": global_index,
"local_dp_rank": local_index,
},
)
)
...
data_parallel = vllm_config.parallel_config.data_parallel_size > 1
try:
for proc, local_dp_rank in zip(self.processes, local_dp_ranks):
...
proc.start()
finally:
# Kill other procs if not all are running.
if self.finished_procs():
self.close()
process 1: engine_core
到这里基本可以看到process0和process1之间的通信是通过传进来的handshake_address来传递地址的 通过两个amq的input_socket和output_socket进行通信的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
class EngineCoreProc(EngineCore):
...
def __init__(
...
):
self.input_queue = queue.Queue[tuple[EngineCoreRequestType, Any]]()
self.output_queue = queue.Queue[tuple[int, EngineCoreOutputs] | bytes]()
...
with self._perform_handshakes(
handshake_address,
identity,
local_client,
vllm_config,
client_handshake_address,
) as addresses:
...
super().__init__(
vllm_config, executor_class, log_stats, executor_fail_callback
)
...
# 这里的input_socket是AMQ的连接,在process_input_sockets中连接
ready_event = threading.Event()
input_thread = threading.Thread(
target=self.process_input_sockets,
args=(
addresses.inputs,
addresses.coordinator_input,
identity,
ready_event,
),
daemon=True,
)
input_thread.start()
# 创建output_socket,将output_queue中的数据发送出去
self.output_thread = threading.Thread(
target=self.process_output_sockets,
args=(
addresses.outputs,
addresses.coordinator_output,
self.engine_index,
),
daemon=True,
)
self.output_thread.start()
...
初始化executor
在父类EngineCore中直接初始化了executor
在获取executor_class的时候单机多卡和单机单卡不一样了,从uni变成了mp 具体的判断逻辑可以参考vllm/config/parallel.py中的__post_init__函数
有4种类型Executor:
- mp:MultiprocExecutor 适用场景:单机多卡。当单机的卡数满足分布式配置,且没有正在运行的ray时使用mp 在mp的情况下,Executor成为一个主进程,其下的若干个workers构成了它的子进程们
- ray:RayDistributedExecutor 适用场景:多机多卡 在ray的情况下,Executor成为一个ray driver process,其下管控若干个worker process
- uni:UniProcExecutor 适用场景:单卡或 Neuron环境
- external_launcher:ExecutorWithExternalLauncher 适用场景:想要用自定义的外部工具(例如Slurm)来做分布式管理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
vllm / config / parallel.py
def __post_init():
...
# world_size=pp_size*tp_size,因此如果是单机多卡,则pp_size=1,tp_size是大于1的
if self.distributed_executor_backend is None and self.world_size > 1:
# We use multiprocessing by default if world_size fits on the
# current node and we aren't in a ray placement group.
from vllm.v1.executor import ray_utils
# 默认是mp
backend: DistributedExecutorBackend = "mp"
ray_found = ray_utils.ray_is_available()
if current_platform.is_tpu() and envs.VLLM_XLA_USE_SPMD:
backend = "uni"
elif (
current_platform.is_cuda()
and cuda_device_count_stateless() < self.world_size
):
if not ray_found:
raise ValueError(
"Unable to load Ray: "
f"{ray_utils.ray_import_err}. Ray is "
"required for multi-node inference, "
"please install Ray with `pip install "
"ray`."
)
# 当前是N卡,但是数量小于world_size,说明是多节点分布式推理,后端是ray
backend = "ray"
elif self.data_parallel_backend == "ray":
logger.info(
"Using ray distributed inference because "
"data_parallel_backend is ray"
)
backend = "ray"
elif ray_found:
if self.placement_group:
backend = "ray"
else:
from ray import is_initialized as ray_is_initialized
if ray_is_initialized():
from ray.util import get_current_placement_group
if get_current_placement_group():
backend = "ray"
self.distributed_executor_backend = backend
logger.debug("Defaulting to use %s for distributed inference", backend)
# 单机单卡world_size=1了,所以excutor_backend就是uni
if self.distributed_executor_backend is None and self.world_size == 1:
self.distributed_executor_backend = "uni"
if self.max_parallel_loading_workers is not None:
logger.warning(
"max_parallel_loading_workers is currently "
"not supported and will be ignored."
)
创建worker进程
这里rpc_broadcast_mq和worker_response_mq是用来executor<->worker之间通信的zmq socket 这里的worker数量是pp_sizetp_size,也就是节点数节点中GPU卡数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
class MultiprocExecutor(Executor):
supports_pp: bool = True
def _init_executor(self) -> None:
...
assert self.world_size == tensor_parallel_size * pp_parallel_size, (
f"world_size ({self.world_size}) must be equal to the "
f"tensor_parallel_size ({tensor_parallel_size}) x pipeline"
f"_parallel_size ({pp_parallel_size}). "
)
...
# 设置share memory模式中最大的数据传输值,这里是16M
max_chunk_bytes = envs.VLLM_MQ_MAX_CHUNK_BYTES_MB * 1024 * 1024
# executor<-->worker之间的input通信连接,这里如果是本地通信使用share memory方式
# 如果是跨节点的或者数据量超过16M后使用zmq socket方式,细节可以查看MessageQueue
self.rpc_broadcast_mq = MessageQueue(
self.world_size, self.world_size, max_chunk_bytes=max_chunk_bytes
)
scheduler_output_handle = self.rpc_broadcast_mq.export_handle()
# 根据world_size数量创建对应数量的worker,可以认为是节点数*每个节点上的gpu数量=world_size
try:
for rank in range(self.world_size):
unready_workers.append(
WorkerProc.make_worker_process(
vllm_config=self.vllm_config,
local_rank=rank,
rank=rank,
distributed_init_method=distributed_init_method,
input_shm_handle=scheduler_output_handle,
shared_worker_lock=shared_worker_lock,
)
)
# 等待所有worker中的input/output socket和executor建立连接成功
...
对于本地的worker,数据量大于16M使用zmq socket通信,小于16M的数据通过share memory的方式传递的,也就是图中rpc部分(small input/output data)
到了这里我们做个总结:
- core_engine_manager和core_engine之间通过zmq socket进行通信,将input queue中的数据通过input socket发送到core_engine。接受output socket中的数据处理后放到output queue中
- core_engine(executor)和worker之间通过大于16M数据的通过zmq socket进行通信,小于16M的时候如果是本地通信通过share memory通信,不然还是用zmq socket
process2: worker
这里的distributed_init_method包含了input socket的地址,在worker中使用rpc_broadcast_mq去进行通信 worker_response_mq是output socket,executor会从这里获取output数据的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
class WorkerProc:
READY_STR = "READY"
def __init__(
...
):
self.rank = rank
wrapper = WorkerWrapperBase(vllm_config=vllm_config, rpc_rank=rank)
# TODO: move `init_worker` to executor level as a collective rpc call
all_kwargs: list[dict] = [
{} for _ in range(vllm_config.parallel_config.world_size)
]
is_driver_worker = rank % vllm_config.parallel_config.tensor_parallel_size == 0
all_kwargs[rank] = {
"vllm_config": vllm_config,
"local_rank": local_rank,
"rank": rank,
"distributed_init_method": distributed_init_method,
"is_driver_worker": is_driver_worker,
"shared_worker_lock": shared_worker_lock,
}
wrapper.init_worker(all_kwargs)
self.worker = wrapper
# 连接executor的rpc_broadcast_mq
self.rpc_broadcast_mq = MessageQueue.create_from_handle(
input_shm_handle, self.worker.rank
)
# 创建worker_response_mq,方式和创建rpc_broadcast_mq一致
self.worker_response_mq = MessageQueue(1, 1)
...
# 初始化gpu设备
self.worker.init_device()
# Set process title and log prefix
self.setup_proc_title_and_log_prefix(
enable_ep=vllm_config.parallel_config.enable_expert_parallel
)
# 加载模型
self.worker.load_model()
从上面可以看出,单机多卡的场景下(多级多卡也是这样的),executor只有一个,每张卡会创建一个worker与之对应。 每个worker需要和executor通过rpc_broadcast_mq接受input数据,同时每个executor会通过worker_response_mq来接受worker的output数据
设备准备
在为每张GPU卡创建对应的worker时,会执行init_device函数,这里会根据GPU卡的厂商调用对应的init_device函数 看起来要支持国产GPU卡,厂商在这里是需要修改vllm代码,调用厂商自己的GPU驱动
模型准备
和上一篇中模型加载流程基本是一致的,只是变成了每个worker都需要加载了,这里遗漏了一个问题,就是分布式推理场景下每张GPU卡的kv cache申请流程分析
几个遗留问题
- kv cache的管理:后面新建一篇文章再详细讲解
- 模型加载在kv cache之前,那么是否有可能模型权重文件直接将GPU显存打满
- 调度:后面新建一篇文章再详细讲解
- 多个worker如何只绑定到指定gpu卡上的
这里看看我们创建worker时指定的参数,注意local_rank参数,是一个index,这里就是gpu的编号
class MultiprocExecutor(Executor): supports_pp: bool = True def _init_executor(self) -> None: ... self.world_size = self.parallel_config.world_size tensor_parallel_size = self.parallel_config.tensor_parallel_size pp_parallel_size = self.parallel_config.pipeline_parallel_size assert self.world_size == tensor_parallel_size * pp_parallel_size, ( f"world_size ({self.world_size}) must be equal to the " f"tensor_parallel_size ({tensor_parallel_size}) x pipeline" f"_parallel_size ({pp_parallel_size}). " ) ... try: for rank in range(self.world_size): unready_workers.append( WorkerProc.make_worker_process( vllm_config=self.vllm_config, local_rank=rank, rank=rank, distributed_init_method=distributed_init_method, input_shm_handle=scheduler_output_handle, shared_worker_lock=shared_worker_lock, ) ) ...在看看这个rank最终是怎么使用的,注重调用了torch的init_process_group函数
-
这里的rank和local rank的区别说明很清晰。local rank表面当前节点上的GPU编号,rank是全局的
class GroupCoordinator: # available attributes: rank: int # global rank ranks: list[int] # global ranks in the group world_size: int # size of the group # difference between `local_rank` and `rank_in_group`: # if we have a group of size 4 across two nodes: # Process | Node | Rank | Local Rank | Rank in Group # 0 | 0 | 0 | 0 | 0 # 1 | 0 | 1 | 1 | 1 # 2 | 1 | 2 | 0 | 2 # 3 | 1 | 3 | 1 | 3 local_rank: int # local rank used to assign devices rank_in_group: int # rank inside the group cpu_group: ProcessGroup # group for CPU communication device_group: ProcessGroup # group for device communication # device communicator (if use_device_communicator=True) device_communicator: DeviceCommunicatorBase | None mq_broadcaster: Any | None # shared memory broadcaster def __init__( ... ): ... self.rank = torch.distributed.get_rank() self.local_rank = local_rank self_device_group = None self_cpu_group = None ... # 来了,这里将worker和节点上具体的gpu进行绑定 if current_platform.is_cuda_alike(): self.device = torch.device(f"cuda:{local_rank}") elif current_platform.is_xpu(): self.device = torch.device(f"xpu:{local_rank}") elif current_platform.is_out_of_tree(): self.device = torch.device(f"{current_platform.device_name}:{local_rank}") else: self.device = torch.device("cpu")